In attempting to build my own implementation of an interprocess queue, I was faced with two basic design issues related to the requirements I placed on myself. The first requirement was to be able to dynamically grow the queue based on demand for memory, and the second requirement was to allow arbitrary sized messages. I wanted no preallocation or explicit limitations. So the design had to allow the shared memory to grow, and for all processes to be able to detect the increase and adjust as needed concurrently. Secondly, I needed to track arbitrary allocations and deallocations within the shared memory object.
Initially, a single page of 4096 bytes is allocated in shared memory, which for Linux resides in /dev/shm on the file system. The initial allocation looks like the diagram below:
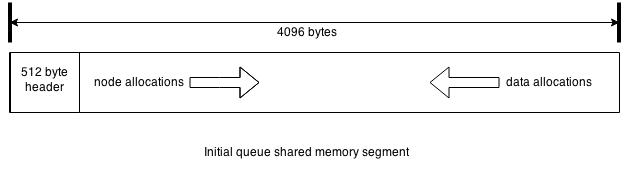
For all processes to be able to use the queue when accessing at different virtual addresses, the memory is treated as an array of signed 64-bit integers so that the embedded data structures are all updated based on calculated offsets instead of pointers. There is a 512-byte header that contains the base of all the basic embedded data structures. Those data structures include three separate semaphores, lock-free lists for the queues, and a critbit tree for tracking freed data allocations. Both the critbit tree and the lists use the same size internal nodes, which have to be double-word aligned. All node allocations are performed from the left to guarantee alignment, whereas, the data allocations can be an arbitrary number of array slots proceed from the right when looking at the diagram. The array is always grown in multiples of 4096-byte page size and the allocation schemes for each type is maintained by advancing the allocation counters to the left and right of the newly allocated pages.
Unfortunately, I could not figure out a way to manage a lock-free concurrent expansion across multiple processes so I had to use a dedicated semaphore in the header as a mutex such that only one process at a time can expand the shared memory. That way any accessing process is able to safely expand using ftruncate() through the use of a shared semaphore. Every access of the shared memory by other processes is guarded by a range check on the index to make sure it is in bounds, otherwise, the enlarged shared memory is remapped before proceeding. In this manner, I am able to have any given process expand the shared memory queue and have all other processes detect and adjust.
As previously mentioned, I use a critbit tree to track freed data allocations based on the implementation described in this paper. I chose that particular data structure because it minimizes the number of internal nodes which minimizes the memory references. I believe that in typical usage that messages on the queue will grouped within a typical range so that the tree in most cases will remain quite small. The key used is the number of 64-bit integer slots in the array the memory allocation occupies, which means that endianness of the native CPU architecture affects the implementation. Since I have access to only Intel CPUs, the code is written for little-endian integer keys.
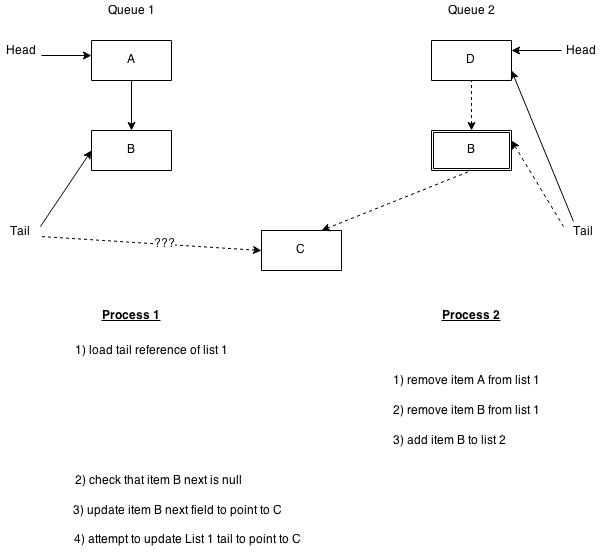
The actual queue is built based on the lock-free queue implementation described by Maged Michael and Michael Scott in this paper. It is probably the best known and most widely used lock-free queue algorithm. Doug Lea used it as the basis for concurrent queues in java.util.concurrent libraries for Java. The book The Art of Multiprocessor Programming by Maurice Herlihy and Nir Shavit also describes the algorithms involved and the issues surrounding them in detail. There are two explicit queues embedded with one for messages and the other for events. Also, when internal nodes are freed, they are essentially queued on a free list.
The conceptual diagram below illustrates a queue with a couple of items enqueued:
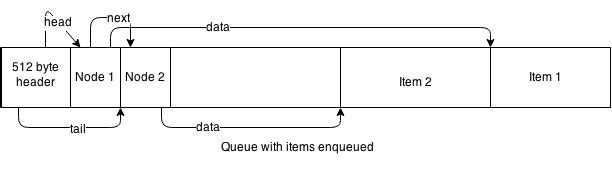
In the diagram, I use the arrows as if they are pointers, where in the actual implementation they are actually integer index references rather than pointer addresses on heap as would be done in a typical single process implementation. The data for each item on queue is shown allocated to the right hand side, and queue nodes are allocated on the left. Only node allocations end up on the actual queue. Each node has a reference to the data location and the next node on queue. Lastly, there is both a head reference and a tail reference maintained in the header portion of the shared memory segment.
Finally, there are two more semaphores that are used to track the size of the queue and allow the calling processes to block either because the queue is empty or that the queue is full. The write semaphore is initialized to the maximum size and will allow writers to add items to queue only if it is not zero. Every add to the queue decrements the count and every remove increments the count. The read semaphore works just the opposite in that it is initialized to zero and reads from queue will block until something has been added. Every add increments the semaphore count and every remove decrements the count. By using two semaphores in such a manner, I am able to create a bounded queue that allows calling processes to block or not block as needed on both the adds and removes. An unbounded queue is approximated by setting the write semaphore to the maximum value for a semaphore, which on a 64-bit Linux system allows 2147483648 items to be added to a queue.