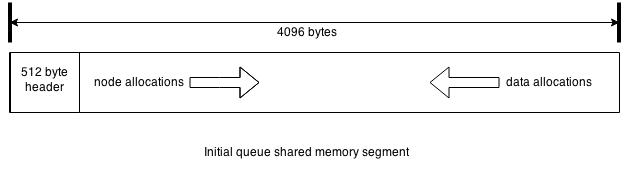
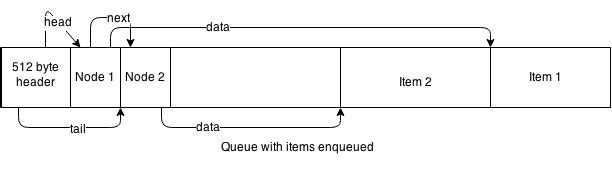
As I stated in the previous post, the actual queue is built based on the lock-free queue implementation described by Maged Michael and Michael Scott in this paper, and that it is probably the best known and most widely used lock-free queue algorithm. Doug Lea used it as the basis for concurrent linke queues in java.util.concurrent libraries for Java. In the paper, the authors address a major problem with lock-free programming known as the ABA problem, where between the read and update another process changes the value from A to B and back to A so that the queue is not in the same state though the pointers in first process have not changed. The well-known solution is to add a generation counter and use a double-word compare_and_swap instruction, which is what my implementation does. The Java implementation does not have the same issue because of garbage collection since the first thread would hold a reference to A it could never be reused. The shared queue uses the counter and double-word CAS instruction to prevent ABA issues since it is implemented in shared memory with no possibility of garbage collection.
While stress testing the shared memory queue, I found another problem with the use of the Michael-Scott algorithm in addition to the ABA problem. I stumbled across the problem while stress testing mostly because I use multiple queues using the same memory in close proximity starting at the same initial state for the generational counters, which dramatically increased the probability of occurrence. The problematic algorithm below is from the paper:
1 | enqueue(Q: pointer to queue t, value: data type) |
The problem begins after line E7 where an executing process is suspended before the CAS at line E9, either before or after line E8. The following diagram illustrates the steps that can occur with concurrently executing processes:
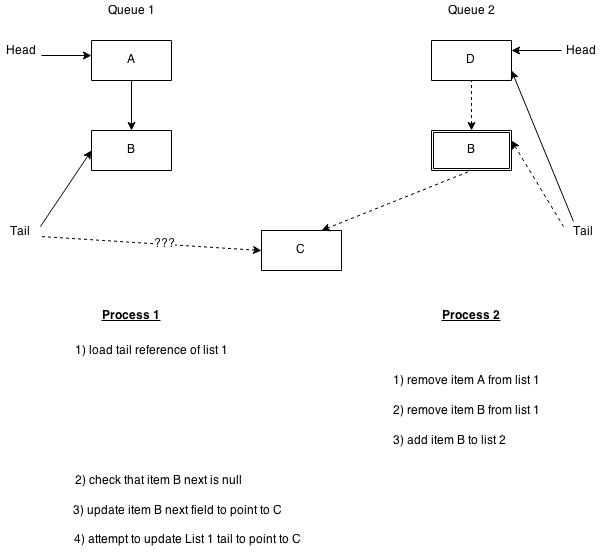
Step 1 for process 1 begins after line E7 where it gets suspended while attempting to add an item at the end of queue 1. At that point, another process can remove the items on the queue including item B which is the tail item for process 1. Then if item B is added to the end of queue 2, it looks to be in the same state as it was in the end of queue 1. If the generation counters for the two queues contain the same value, for instance because the items are bouncing between the queues, process 1 will succeed when it resumes and performs the CAS at line E9. Line E17 will fail because the tail has changed, so the item is incompletely on queue 2 instead of queue 1 and the queue 2 tail is not advanced correctly. I believe the Java implementation is not protected from this issue either based on the code I downloaded from Doug Lea’s homepage if the next field is set to null for any reason after being removed from queue.
I came up with two alternative solutions to the problem. The simpler one for my shared memory queue implementation was to intialize the generation counters to separate ranges of integer values that would not likely overlap since it is based on a 64-bit architecture where the integers will not wrap. Technically one range could end up overlapping the other, in which case the problem would occur again, but I make the ranges so far apart that it would be almost impossible. The other alternative is to use a unique value as the end of queue value in the next field instead of null, which would also be needed for Java. That could be the parent queue structure address, for instance, or some empty node value allocated for each queue, but the only requirement is that it be unique for each queue instance.